인덱스를 걸었는데, 왜 느리죠? (feat. 5초를 0.03초로 만든 쿼리 삽질기)
이커머스 서비스에서 가격, 최신순, 인기순으로 상품 목록을 보여주는 것은 지극히 평범하고도 필수적인 기능이다
개발 단계의 적은 데이터에서는 드러나지 않는 성능 병목을 확인하기 위해, 의미 있는 규모의 테스트 데이터(상품 50만, 좋아요 10만)를 채워 넣고 마지막 관문인 성능 테스트를 시작했다.
이때 가장 중요한 것은 정확한 병목 지점을 찾는 것이었다. 여러 사용자로 테스트하면 네트워크나 서버 경합 등 다른 변수가 섞일 수 있기에, 변인 통제를 위해 오직 가상 사용자 1명(1 VU)으로 1분간 API를 반복 호출하여 순수한 API 처리 성능의 베이스라인을 측정하기로 했다.
측정 결과 평균 응답 시간이 10초를 훌쩍 넘는 믿기 힘든 결과가 나왔다.
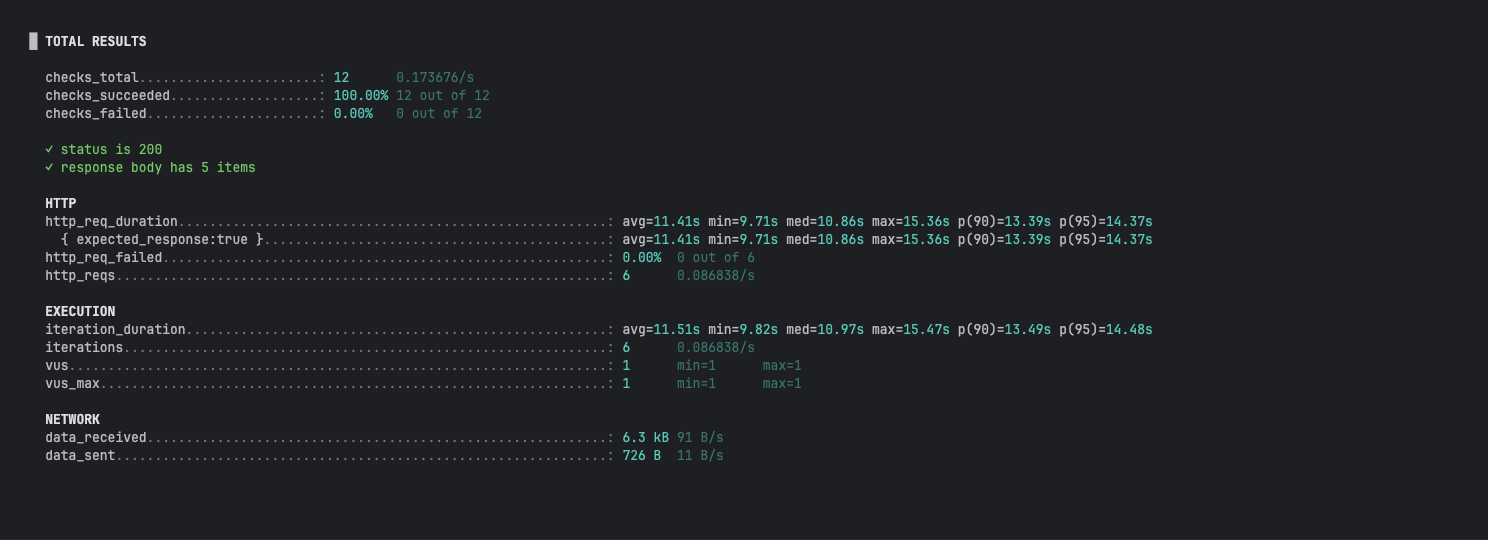
DB 클라이언트에서 직접 쿼리를 실행해 보았다.
5 rows in set (5.38 sec)단 5개의 데이터를 가져오는 데 5초 이상이 소요되고 있었다.
문제의 원인을 찾기 위해 곧바로 쿼리 분석에 들어갔다.
GROUP BY가 ORDER BY 인덱스를 막는 순간
가장 먼저 의심한 곳은 product_like 테이블과 JOIN하여 좋아요 수를 집계하는 GROUP BY 구문이었다.
처음 쿼리를 설계할 때는 여러 번 쿼리를 날리는 서브쿼리보다, 단일 쿼리로 모든 정보를 가져오는 JOIN 방식이 더 효율적일 것이라는 막연한 믿음이 있었다.
SELECT
p.id
,p.price
,p.name
,b.name
, count(pl.id) as likeCount
, p.released_at FROM
product p
LEFT JOIN brand b ON b.id = p.ref_brand_id
LEFT JOIN product_like pl ON p.id = pl.ref_product_id
GROUP BY
p.id
, p.price
,p.name
, b.name
, p.released_at
ORDER BY p.price ASC
LIMIT 5 OFFSET 0;EXPLAIN으로 실행 계획을 확인하자, 나의 믿음이 어떻게 잘못되었는지 명확하게 드러났다.
id | select_type | table | type | key | rows | Extra
---|-------------|-------|-------|-----------------------------|--------|---------------------------------------------------------
1 | SIMPLE | p | ALL | NULL | 497193 | Using temporary; Using filesort
1 | SIMPLE | b | eq_ref| PRIMARY | 1 | NULL
1 | SIMPLE | pl | index | UKi88ydvxuyj9djsf1yaq18mdpb | 99822 | Using where; Using index; Using join buffer (hash join)
- type: ALL : product 테이블을 풀 스캔하고 있다. 인덱스를 전혀 활용하지 못하고 50만 건의 데이터를 모두 읽고 있다는 의미다.
- Extra: Using temporary; Using filesort : 성능 저하의 주범이다.
GROUP BY와ORDER BY를 함께 처리하기 위해, 데이터베이스는 조인과 집계가 끝난 거대한 중간 결과물을 임시 테이블에 저장(Using temporary)한 뒤, 이 임시 테이블을 다시 정렬(Using filesort)하는 최악의 시나리오로 동작하고 있었다. LIMIT 5는 이 모든 비효율적인 작업이 끝난 후에야 적용된다.
왜 price 인덱스가 안 타지? (GROUP BY의 우선순위)
"풀 스캔과 filesort가 문제라면, 정렬 컬럼에 인덱스를 걸면 해결될 것이다."
가장 단순하고 명쾌한 해결책이라고 생각했다. ORDER BY의 대상인 product 테이블 price 컬럼에 B-Tree 인덱스를 생성했다.
이제 옵티마이저가 당연히 이 인덱스를 타고 filesort를 건너뛸 것이라고 확신했다. 그리고 다시 쿼리를 실행했다.
5 rows in set (5.35 sec)결과는 처참했다. 5.38초가 5.35초 가 된 것은 오차 범위일 뿐, 아무것도 해결되지 않았다. 당혹스러운 마음에 다시 실행 계획을 확인했다.
+----+-------------+-------+------+---------+-----------------------------------+
| id | select_type | table | type | rows | Extra |
+----+-------------+-------+------+---------+-----------------------------------+
| 1 | SIMPLE | p | ALL | 497349 | Using temporary; Using filesort |
...
변한 것이 아무것도 없었다. product 테이블은 여전히 type: ALL로 풀 스캔되고 있었고, Extra에는 Using filesort가 선명하게 남아있었다.
인덱스를 분명히 만들었는데, 왜 데이터베이스는 사용조차 하지 않는 걸까?
이유는 데이터베이스의 실행 순서에 있었다.
옵티마이저는 ORDER BY 절을 처리하기 전에, GROUP BY 절을 먼저 수행하여 likeCount를 계산해야 한다.
이 집계 연산은 테이블의 전체 데이터를 대상으로 할 수밖에 없으므로, 옵티마이저는 price 인덱스를 사용하여 5개만 미리 뽑아내는 최적화를 포기해버린다.
결국 옵티마이저는 다음과 같은 순서로 동작한다.
- 50만 개 상품 전체를
JOIN,GROUP BY하여 likeCount가 포함된 거대한 임시 테이블 생성 - 이 인덱스가 없는 임시 테이블을 price 기준으로 정렬
- price 인덱스는 원본 테이블에만 존재할 뿐, 이 임시 테이블에는 없으므로 무용지물
이 비효율적인 과정을 도식으로 표현하면 다음과 같다
A. 초기(느린) 경로 — JOIN + GROUP BY + ORDER BY
product (Full scan: 50만)
└─ LEFT JOIN product_like
└─ GROUP BY (임시 테이블 생성)
└─ ORDER BY price (Using filesort)
└─ LIMIT 5JOIN 자체의 성능 문제일까 싶어,
이번에는 product_like 테이블의 ref_product_id 컬럼에도 인덱스를 추가한 뒤 실행 계획을 확인 해보았다.
+----+-------------+-------+------+---------+---------------------------------+
| id | select_type | table | type | rows | Extra |
+----+-------------+-------+------+---------+---------------------------------+
| 1 | SIMPLE | p | ALL | 497349 | Using temporary; Using filesort |
| ...| ... | ... | ... | ... |
| 1 | SIMPLE | pl | ref | 1 | Using index |
+----+-------------+-------+------+---------+---------------------------------+product_like 테이블의 실행 계획이 type: index에서 type: ref로 개선되며 조인 자체는 빨라졌다.
하지만 가장 큰 문제인 product 테이블의 type: ALL과 Using filesort는 조금도 변하지 않았다.
쿼리 시간은 여전히 5초대에 머물렀다. GROUP BY 절은 ORDER BY 절보다 먼저 실행되어 테이블 전체를 대상으로 집계 연산을 수행해야 한다. 이 과정에서 생성되는 임시 테이블에는 price 인덱스가 없으므로, 결국 ORDER BY를 위한 인덱스 최적화는 원천적으로 불가능했다.
먼저 줄이고 나중에 계산한다: 서브쿼리 + LIMIT 전략
GROUP BY라는 거대한 벽 앞에서 인덱스가 무력해지는 것을 확인한 나는, 문제 해결의 방향을 완전히 틀어야 했다. 인덱스 튜닝이 아니라, 쿼리 구조 자체를 변경하기로 결심했다.
나는 GROUP BY를 제거하고, likeCount를 SELECT 절의 스칼라 서브쿼리로 가져오는 방식으로 쿼리를 수정했다.
-- 최적화된 쿼리 (스칼라 서브쿼리)
SELECT
p.id, p.price, p.name, b.name,
(SELECT count(*) FROM product_like pl WHERE pl.ref_product_id = p.id) as likeCount,
p.released_at
FROM product p
LEFT JOIN brand b ON b.id = p.ref_brand_id
ORDER BY p.price ASC
LIMIT 5 OFFSET 0;구조 변경만 적용했을 때: 절반의 성공
먼저, product 테이블의 모든 인덱스를 제거하고 순수하게 쿼리 구조 변경의 효과만 확인해 보았다.
5 rows in set (0.63 sec)5.38초에 비하면 엄청난 발전이다. 8배 이상 빨라졌다. GROUP BY를 제거한 것만으로도 상당한 성능 개선이 이루어진 것이다.
하지만 0.63초 역시 만족스러운 속도는 아니었다. EXPLAIN을 통해 그 이유를 파헤쳐 보았다.
+----+-------------+-------+------+---------+----------------+
| id | select_type | table | type | rows | Extra |
+----+-------------+-------+------+---------+----------------+
| 1 | PRIMARY | p | ALL | 497193 | Using filesort |
...type: ALL및Extra: Using filesort: 여전히 product 테이블은 풀 스캔되고 있었고, filesort가 발생하고 있었다. price 인덱스가 없으니 당연한 결과다.- 달라진 점: 이전과 달리,
Using temporary가 사라졌다. GROUP BY가 없어지면서 거대한 임시 테이블을 만들 필요가 없어졌고, filesort의 대상도 JOIN과 집계가 포함된 복잡한 결과가 아닌 product 테이블 자체로 단순화되었다.
이것이5.38초가0.63초로 줄어든 핵심 이유다.
구조 변경은 temporary table이라는 가장 무거운 족쇄 하나를 풀어주었지만, filesort라는 족쇄는 여전히 남아있었다.
구조 변경 + 인덱스: 진정한 시너지의 발현
이제 이 새로운 쿼리 구조에 날개를 달아줄 차례다. product(price) 컬럼에 다시 인덱스를 생성했다.
5 rows in set (0.06 sec)결과는 경이로웠다. 0.63초가 0.06초로, 다시 10배 이상 빨라졌다.
JOIN과 GROUP BY가 있던 시절과 비교하면 거의 90배에 가까운 성능 향상이다. EXPLAIN은 이 극적인 변화의 이유를 명확하게 보여주었다.
+----+-------------+-------+-------+-----------+------+-------+
| id | select_type | table | type | key | rows | Extra |
+----+-------------+-------+-------+-----------+------+-------+
| 1 | PRIMARY | p | index | idx_price | 5 | NULL |
...type: index:ALL이index로 바뀌었다. 이제 옵티마이저는price인덱스를 보고 테이블 전체를 읽는 대신, 인덱스만 읽어서 처리한다.
rows: 5: 처리할 예상 행 수가 50만에서 단 5로 줄었다.ORDER BY와LIMIT을 보고, 필요한 만큼만 읽으면 된다는 것을 완벽하게 인지한 것이다.Extra: NULL: 마침내Using filesort가 사라졌다. 인덱스 자체가 이미price순으로 정렬되어 있으므로, 별도의 정렬 작업이 전혀 필요 없어진 것이다.
이전의 JOIN은 "선 계산, 후 정렬" 방식으로 50만 개 전체를 대상으로 무거운 작업을 했다면, 서브쿼리 방식은 "선 정렬 및 범위 축소, 후계산" 방식으로 동작했다.
즉, ORDER BY와 LIMIT으로 5개의 대상을 먼저 추려낸 뒤, 그 5개에 대해서만 서브쿼리를 실행하여 작업의 총량을 극적으로 줄인 것이다.
좋은 쿼리 구조(서브쿼리)와 좋은 인덱스(price)가 만났을 때 비로소 최적의 성능이 나온다는 것을 데이터로 증명한 순간이었다.
B. 구조 변경 — “선정렬·축소 후 계산”(서브쿼리)
product
└─ ORDER BY price (인덱스 가능)
└─ LIMIT 5 (상위 5개)
└─ 각 행마다 (SELECT COUNT(*) FROM product_like WHERE ref_product_id = p.id)읽기 전용 집계 테이블 (비정규화) 도입
서브쿼리 방식은 훌륭했지만, 조회할 때마다 Count 를 계산하는 작업이 마음에 걸렸다. 읽기 성능을 극한으로 끌어올리기 위해, 나는 비정규화를 도입하기로 결정했다.
'좋아요' 이벤트가 발생할 때 마다 집계된 like_count 를 저장하는 like_summary 테이블을 별도로 만들었다.
이제 조회 쿼리는 실시간 집계 없이, 미리 계산된 값을 join 으로 가져오기만 하면 된다.
이 새로운 모델이 기존의 '가격순 정렬'에서도 문제없이 동작하는지 먼저 확인하고, 그 다음 이 모델의 진짜 목적인 '좋아요순 정렬'의 성능을 확인해 보기로 했다
가격순 정렬: 새로운 모델의 기본 성능 확인
-- 비정규화 모델 쿼리
SELECT
p.id, p.price, p.name, b.name AS brandName,
COALESCE(s.like_count, 0) AS likeCount,
p.released_at
FROM product p
LEFT JOIN brand b ON p.ref_brand_id = b.id
LEFT JOIN like_summary s ON s.target_id = p.id AND s.target_type = 'PRODUCT'
ORDER BY p.price DESC
LIMIT 5 OFFSET 0;먼저 기존과 동일하게 price로 정렬하는 쿼리를 테스트했다. product(price) 인덱스가 있는 상태에서 실행 시간은 0.05초로,
이전 서브쿼리 모델과 비슷하거나 미세하게 더 빠른 결과를 보였다.
5 rows in set (0.05 sec)실행 계획은 다음과 같이 filesort 없이 완벽하게 동작했다.
id | table | type | key | rows | Extra
---|-------|--------|-----------|------|-----------------------
1 | p | index | idx_price | 5 |
1 | b | eq_ref | PRIMARY | 1 |
1 | s | eq_ref | UK... | 1 | Using index condition
옵티마이저가 product 테이블의 idx_price를 타고, brand와 like_summary는 이미 존재하는 인덱스를 통해 효율적으로 조인하고 있었다.
실시간 집계의 부하가 사라진 덕분에 안정적인 성능을 보여주었다.
좋아요순 정렬: 비정규화 모델의 진짜 시험대
이제 이 모델을 도입한 진짜 이유, '좋아요순 정렬' 을 테스트할 차례다.
-- 비정규화 모델 쿼리
SELECT
p.id, p.price, p.name, b.name AS brandName,
COALESCE(s.like_count, 0) AS likeCount,
p.released_at
FROM product p
LEFT JOIN brand b ON p.ref_brand_id = b.id
LEFT JOIN like_summary s ON s.target_id = p.id AND s.target_type = 'PRODUCT'
ORDER BY s.like_count DESC
LIMIT 5 OFFSET 0;'좋아요순' 정렬을 테스트하자, 쿼리 시간은 1.92초. 다시 원점으로 돌아온 듯했다.
id | select_type | table | type | key | rows | Extra
---|-------------|-------|-------|-----------------------------|--------|---------------------------------
1 | SIMPLE | p | ALL | NULL | 497349 | Using temporary; Using filesort
1 | SIMPLE | b | eq_ref| PRIMARY | 1 | NULL
1 | SIMPLE | s | eq_ref| UKaqw1do2xdd90a3o0aneikiq8y | 1 | Using index condition
EXPLAIN 을 확인하니, 또 다시 product 테이블을 풀 스캔하면 Using filesort 가 발생하고 있었다.
like_summary 테이블에는 (target_id , target_type) 인덱스가 잘 걸려 있었지만 , 정렬 기준인 like_count 컬럼에는 인덱스가 없었다.
단일 인덱스의 순진한 기대
가장 먼저 떠오르는 해결책은 단순했다.
like_summary 테이블의 like_count 컬럼에 단일 인덱스를 추가하는 것이다.
Table | Key_name | Column_name | Cardinality | Index_type
-------------|-----------------------------|-------------|-------------|-----------
like_summary | PRIMARY | id | 430750 | BTREE
like_summary | UKaqw1do2xdd90a3o0aneikiq8y | target_id | 430750 | BTREE
like_summary | UKaqw1do2xdd90a3o0aneikiq8y | target_type | 430750 | BTREE
like_summary | idx_like_count | like_count | 11 | BTREE
이제 옵티마이저가 이 인덱스를 타고 filesort를 피할 것이라고 기대했다. 하지만 결과는 나를 비웃는 듯했다.
5 rows in set (1.86 sec)실행 시간은 거의 그대로였고, 실행 계획 역시 이전과 100% 동일했다. 옵티마이저는 내가 만든 idx_like_count를 완전히 무시했다.
id | select_type | table | type | key | rows | Extra
---|-------------|-------|-------|-----------------------------|--------|---------------------------------
1 | SIMPLE | p | ALL | NULL | 497349 | Using temporary; Using filesort
1 | SIMPLE | b | eq_ref| PRIMARY | 1 | NULL
1 | SIMPLE | s | eq_ref| UKaqw1do2xdd90a3o0aneikiq8y | 1 | Using index condition
왜일까? 옵티마이저는 '비용(Cost)' 기반으로 생각한다.
이 쿼리에는 s.target_type = 'PRODUCT'라는 숨겨진 필터 조건이 있다.
옵티마이저 입장에서 idx_like_count만 사용하면, 'PRODUCT' 타입이 아닌 다른 타입의 데이터까지 모두 읽은 뒤에 필터링해야 하는 비효율이 발생할 수 있다.
결국 옵티마이저는 "그렇게 하느니 차라리 product 테이블 전체를 읽고 정렬하는 게 낫겠다"고 판단해버린 것이다.
복합 인덱스의 배신, 그리고 의문
"아, 필터링 조건도 함께 넣어줘야 하는구나!"
나는 필터링(target_type)과 정렬(like_count)을 모두 포함하는 복합 인덱스를 생성했다.
이것이야말로 정답이라고 확신했다.
Table | Key_name | Column(s) | Non_unique | Cardinality | Index_type
--------------|------------------------------|---------------------|------------|------------|-----------
like_summary | PRIMARY | id | 0 | 430750 | BTREE
like_summary | UKaqw1do2xdd90a3o0aneikiq8y | target_id, target_type | 0 | 430750 | BTREE
like_summary | idx_target_type_like_count | target_type, like_count | 1 | 11 | BTREE
하지만 결과는 다시 한번 나를 좌절시켰다. 실행 시간은 1.84초,
실행 계획은 여전히 product 테이블을 풀 스캔하며 Using filesort를 수행하고 있었다
id | table | type | key | rows | Extra
---|-------|--------|-----------------------------|------|-------------------------------
1 | p | ALL | NULL | 497349 | Using temporary; Using filesort
1 | b | eq_ref | PRIMARY | 1 |
1 | s | eq_ref | UKaqw1do2xdd90a3o0aneikiq8y | 1 | Using index condition
분명히 쿼리의 모든 조건을 만족하는 완벽한 인덱스를 만들었는데, 왜 옵티마이저는 계속해서 가장 비효율적인 길을 고집하는 걸까?
여기서 나는 문제의 본질이 인덱스 자체가 아니라, 데이터베이스가 일하는 방식에 있음을 깨달았다.
Driving Table을 바꾸면 0.03초가 보인다
해답은 Driving Table 과 Driven Table 개념에 있었다.
JOIN 시 가장 먼저 읽는 기준 테이블이 Driving Table 이고, 그 결과에 따라 나중에 참조되는 테이블이 Driven Table 이다.
JOIN 성능은 얼마나 작은 Driving Table 을 가지고 시작하는 가에 달려 있다.
옵티마이저는 FROM product p ... 구문을 보고, 50만 건의 product 테이블을 Driving Table로 선택하고 있었다.
즉, 50만 번의 루프를 돌며 like_summary를 찾아 붙인 뒤, 이 거대한 결과물을 통째로 정렬하고 있었던 것이다.
이 방식에서는 like_summary에 만든 그 어떤 인덱스도 정렬에 사용될 수 없다.
우리가 원했던 이상적인 순서는 그 반대였다.
Driving Table: like_summary에서 like_count가 높은 5개를 인덱스를 이용해 먼저 찾는다.Driven Table: 찾아낸 5개를 가지고 product 테이블을 조인한다.
STRAIGHT_JOIN으로 조인 순서 고정 (MySQL)
옵티마이저가 product 테이블을 Driving Table로 선택하는 것을 막기 위해, JOIN 순서를 직접 제어할 필요가 있었다. FROM 절의 테이블 순서를 변경하고 STRAIGHT_JOIN 힌트를 사용하여, like_summary 테이블부터 조인이 시작되도록 쿼리를 수정했다.
SELECT ...
FROM
like_summary s
STRAIGHT_JOIN -- 이 힌트로 JOIN 순서를 고정!
product p ON s.target_id = p.id
LEFT JOIN
brand b ON p.ref_brand_id = b.id
WHERE
s.target_type = 'PRODUCT'
ORDER BY
s.like_count DESC
LIMIT 5 OFFSET 0;결과는 완벽했다. 1.84초 걸리던 쿼리가 0.03초로 단축되었다. 실행 계획 또한 의도했던 대로 변경된 것을 확인할 수 있었다.
id | table | type | key | rows | Extra
---|-------|--------|----------------------------|--------|--------------------------------
1 | s | ref | idx_target_type_like_count | 215375 | Using where; Backward index scan
1 | p | eq_ref | PRIMARY | 1 |
1 | b | eq_ref | PRIMARY | 1 |
Driving Table: 시작 테이블이 like_summary(s)로 변경되었다.Extra: Backward index scan: filesort가 사라졌다. 옵티마이저는 우리가 만든 idx_target_type_like_count 복합 인덱스를 뒤에서부터 거꾸로 읽어, 정렬 작업을 하지 않고도 DESC 정렬을 완벽하게 구현했다.
C. 집계 테이블 + 올바른 드라이빙 테이블
like_summary (idx: target_type, like_count) ← 역방향 인덱스 스캔으로 상위 5
└─ JOIN product (PK)
└─ LEFT JOIN brand (PK)성능과 비즈니스 요구사항 사이에서
STRAIGHT_JOIN을 통해 like_summary를 Driving Table로 삼는 순간, 1.84초 걸리던 쿼리는 0.03초로 단축되었다.
하지만 이 완벽해 보이는 해결책에는, 한 가지 치명적인 비즈니스적 함정이 숨어있었다. like_summary를 기준으로 조인을 시작하면, '좋아요가 0개인 상품'은 결과에서 영원히 제외된다. LEFT JOIN을 통해 '좋아요가 없는 상품'도 목록에 포함시키려 했던 초기 요구사항과 정면으로 배치되는 결과였다.
결국, 우리는 근본적인 질문으로 돌아왔다. 이 API의 진짜 주인공은 누구인가?
이 API는 '좋아요 목록 조회'가 아닌, '상품 목록 조회' API다. 대부분의 사용자는 가격순, 최신순으로 상품을 탐색할 것이고, 이때 기준이 되는 테이블은 당연히 product 테이블이다. 즉, product 테이블이 Driving Table이 되는 것이 이 API의 본질에 더 부합했다.
Driving Table 선택의 원칙: ORDER BY가 열쇠를 쥐고 있다
JOIN 튜닝의 핵심은 "어떻게 하면 Driving Table의 작업 범위를 가장 작게 줄일 수 있는가?"이다. 그리고 그 열쇠는 바로 ORDER BY와 LIMIT 절이 쥐고 있다.
옵티마이저가 filesort를 피하는 유일한 방법은, 이미 정렬된 순서대로 데이터를 읽는 것, 즉 인덱스를 활용하는 것이다.
- ORDER BY p.price :
product테이블의 price 인덱스를 순서대로 LIMIT 5 만큼만 읽으면 정렬이 끝난다. - ORDER BY s.like_count :
like_summary테이블의 like_count 인덱스를 순서대로 LIMIT 5 만큼만 읽으면 정렬이 끝난다.
즉, ORDER BY의 대상 컬럼이 속한 테이블이 Driving Table이 되어야만 filesort를 피하고 최고의 성능을 낼 수 있다.
이 원칙은 우리에게 명확한 딜레마를 안겨주었다.
- '가격순/최신순' 정렬을 위해서는 product가 Driving Table이 되어야 한다.
- '좋아요순' 정렬을 위해서는 like_summary가 Driving Table이 되어야 한다.
하나의 쿼리로는 이 두 마리 토끼를 동시에 잡을 수 없었다.
포기가 아닌, 분리(Separation)
그렇다면 우리는 '좋아요순' 정렬의 성능을 포기해야만 할까?
이 지점에서 우리는 데이터베이스의 한계를 애플리케이션의 유연성으로 극복하기로 했다. 모든 정렬 조건을 단 하나의 쿼리로 해결하겠다는 생각을 버리는 것이다.
우리의 Service Layer는 지휘자의 역할을 맡는다. Controller로부터 들어온 정렬 조건을 보고, 그에 맞는 가장 최적화된 '전용 쿼리'를 호출해주는 것이다.
"productSort = PRICE_ASC 또는 LATEST_DESC 요청이 들어오면?"
product를 Driving Table로 삼아 filesort 없이 price 또는 released_at 인덱스를 타는 일반 쿼리를 호출한다.
(성능: 0.05초)
"productSort = LIKE_COUNT_DESC 요청이 들어오면?"
like_summary를 Driving Table로 삼아 filesort 없이 like_count 인덱스를 타는 '좋아요순 전용' 쿼리 (STRAIGHT_JOIN 사용)를 호출한다.
(성능: 0.03초)
이 방식은 '좋아요순' 정렬 시 '좋아요 0개' 상품이 제외된다는 비즈니스적 타협을 동반하지만, "인기 있는 상품을 본다"는 사용자의 의도에 더 부합하는 합리적인 선택이었다.
튜닝 여정 한눈에 보기
이번 5.38초에서 0.03초에 이르는 기나긴 튜닝 여정을 한눈에 요약하면 다음과 같습니다.
| 단계 | 쿼리/전략 | 주요 증상/계획 | 시간 |
|---|---|---|---|
| 1 | JOIN + GROUP BY + ORDER BY |
Using temporary; Using filesort, p: type=ALL |
5.38s |
| 2 | price 인덱스만 추가 |
여전히 GROUP BY가 막음 |
5.35s |
| 3 | 구조변경 (서브쿼리로 likeCount) |
임시테이블 제거, filesort만 남음 |
0.63s |
| 4 | + price 인덱스 활용 |
인덱스 순서로 상위 N만 읽기 | 0.06s |
| 5 | 집계테이블 도입 (ORDER BY price) |
filesort 없음, 안정적인 성능 확인 |
0.05s |
| 6 | 집계테이블 도입 (ORDER BY like_count) |
Using filesort, p가 드라이빙 테이블 |
1.92s |
| 7 | like_count 단일 인덱스 |
옵티마이저가 무시 (비용상 불리) | 1.86s |
| 8 | (target_type, like_count) 복합 인덱스 |
여전히 p가 드라이빙 |
1.84s |
| 9 | STRAIGHT_JOIN로 s → p |
인덱스 역스캔, 상위 N 선별 후 JOIN |
0.03s |
맺으며
인덱스는 감이 아닌 데이터로 설계한다.
이번 성능 튜닝을 통해 배운 교훈을 다시 정리하면 다음과 같다.
-
단일 쿼리의 편리함이 항상 성능을 보장하지는 않았다.
:JOIN과 GROUP BY의 간결함 이면에는Using temporary;Using filesort라는 거대한 비용이 숨어있을 수 있었고, 실행 계획은 그 실제 비용을 보여주는 가장 정직한 지표였다. -
인덱스는 생성보다 '활용'이 더 중요했다.
:쿼리 구조 자체가 인덱스를 활용할 수 없도록 설계되었거나, 옵티마이저가 비효율적인 테이블부터 읽기 시작한다면 인덱스는 무용지물이었다. -
옵티마이저의 판단이 항상 최선은 아니었다.
:비용 기반으로 동작하는 옵티마이저가 데이터의 분포나 쿼리의 복잡성 때문에 때로는 최적의 실행 계획을 찾지 못했다. 이런 상황에서는 STRAIGHT_JOIN 같은 힌트를 통해 개발자가 직접 실행 계획에 개입하는 것이 효과적인 해결책이 될 수 있었다. -
모든 결정은 추측이 아닌 데이터에 기반해야 한다.
:EXPLAIN과 k6가 보여주는 객관적인 데이터만이 '감'에 의존한 예상을 바로잡고, 가장 신뢰할 수 있는 개선의 방향을 알려주었다.
결국 "인덱스를 걸었다"는 사실에 안주하는 것이 아니라, 데이터베이스가 어떻게 동작하는지 이해하고, 실행 계획이라는 데이터를 근거로 꾸준히 의심하고 검증하는 과정이야말로 서비스의 안정성을 지키는 가장 중요한 습관임을 다시 한번 느꼈다.